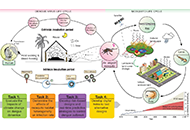







Transmitted primarily by Aedes aegypti (Ae. aegypti) and Aedes albopictus (Ae. albopictus), arboviral diseases pose a major global public health threat. Dengue, chikungunya, and zika are increasingly prevalent in Southeast Asia. Among other arboviruses, dengue and zika are becoming more common in Central and South America. Given human encroachment into previously uninhabited, often deforested areas, to provide new housing in regions of population expansion, conceptualizing built urban environments in a novel way is urgently needed to safeguard against the growing climate change-driven threat of vector-borne diseases. By understanding the spread from a One Health perspective, enhanced control and prevention can be achieved. This is particularly important considering that climate change is likely to significantly impact the persistence of ponded water where mosquitoes breed due to increasing temperature and shifting rainfall patterns with regard to magnitude, duration, frequency, and season. Models can incorporate aquatic mosquito stages and adult spatial dynamics when habitats are heterogeneously available, thereby including dispersal and susceptible-exposed-infected-recovered (SEIR) epidemiology. Coupled with human population distribution (density, locations), atmospheric conditions (air temperature, precipitation), and hydrological conditions (soil moisture distribution, ponding persistence in topographic depressions), modeling has improved predictive ability for infection rates. However, it has not informed interventional approaches from an urban environment perspective which considers the role of ponds/lakes that support green spaces, the density of population that enables rapid spread of disease, and varying micro-habitats for various mosquito stages under climate change. Here, for an example of dengue in Vietnam, a preventive and predictive approach to design resilient urban environments is proposed, which uses data from rapidly expanding metropolitan communities to learn continually. This protocol deploys computational approaches including simulation and machine learning/artificial intelligence, underpinned by surveillance and medical data for validation and adaptive learning. Its application may best inform urban planning in low-middle income countries in tropical zones where arboviral pathogens are prevalent.
Transmitted primarily by Aedes aegypti (Ae. aegypti) and Aedes albopictus (Ae. albopictus), arboviral diseases pose a major global public health threat. Dengue, chikungunya, and zika are increasingly prevalent in Southeast Asia. Among other arboviruses, dengue and zika are becoming more common in Central and South America. Given human encroachment into previously uninhabited, often deforested areas, to provide new housing in regions of population expansion, conceptualizing built urban environments in a novel way is urgently needed to safeguard against the growing climate change-driven threat of vector-borne diseases. By understanding the spread from a One Health perspective, enhanced control and prevention can be achieved. This is particularly important considering that climate change is likely to significantly impact the persistence of ponded water where mosquitoes breed due to increasing temperature and shifting rainfall patterns with regard to magnitude, duration, frequency, and season. Models can incorporate aquatic mosquito stages and adult spatial dynamics when habitats are heterogeneously available, thereby including dispersal and susceptible-exposed-infected-recovered (SEIR) epidemiology. Coupled with human population distribution (density, locations), atmospheric conditions (air temperature, precipitation), and hydrological conditions (soil moisture distribution, ponding persistence in topographic depressions), modeling has improved predictive ability for infection rates. However, it has not informed interventional approaches from an urban environment perspective which considers the role of ponds/lakes that support green spaces, the density of population that enables rapid spread of disease, and varying micro-habitats for various mosquito stages under climate change. Here, for an example of dengue in Vietnam, a preventive and predictive approach to design resilient urban environments is proposed, which uses data from rapidly expanding metropolitan communities to learn continually. This protocol deploys computational approaches including simulation and machine learning/artificial intelligence, underpinned by surveillance and medical data for validation and adaptive learning. Its application may best inform urban planning in low-middle income countries in tropical zones where arboviral pathogens are prevalent.
DOI: https://doi.org/10.37349/edht.2023.00004
X (formerly Twitter), a microblogging social media platform, is being used by scientists and researchers to disseminate their research findings and promote the visibility of their work to the public. Tweets can be posted with text messages, images, hyperlinks, or a combination of these features. Importantly, for the majority of users, the text must be limited to 280 characters. In this perspective, this study aimed to observe if adding an image is able to increase outreach for scientific communication on X. Therefore, the characteristics of tweets posted with the hashtag #SciComm (short for science communication) for a period of one year (28 May 2020 to 28 May 2021) were analyzed with the X analytics tool Symplur Signals. The conducted analysis revealed that when a science communication (#SciComm-containing) tweet is accompanied by an image added by the user, there is on average a 529% increase in the number of retweets, and adding a hyperlink is similarly effective in increasing the number of retweets. However, combining both an image and hyperlink in the same tweet did not yield an additive effect. Hence, for increased visibility, researchers may consider adding images or hyperlinks (e.g., to research publications or popular science articles) while communicating science to the public on X.
X (formerly Twitter), a microblogging social media platform, is being used by scientists and researchers to disseminate their research findings and promote the visibility of their work to the public. Tweets can be posted with text messages, images, hyperlinks, or a combination of these features. Importantly, for the majority of users, the text must be limited to 280 characters. In this perspective, this study aimed to observe if adding an image is able to increase outreach for scientific communication on X. Therefore, the characteristics of tweets posted with the hashtag #SciComm (short for science communication) for a period of one year (28 May 2020 to 28 May 2021) were analyzed with the X analytics tool Symplur Signals. The conducted analysis revealed that when a science communication (#SciComm-containing) tweet is accompanied by an image added by the user, there is on average a 529% increase in the number of retweets, and adding a hyperlink is similarly effective in increasing the number of retweets. However, combining both an image and hyperlink in the same tweet did not yield an additive effect. Hence, for increased visibility, researchers may consider adding images or hyperlinks (e.g., to research publications or popular science articles) while communicating science to the public on X.
DOI: https://doi.org/10.37349/edht.2023.00005
DOI: https://doi.org/10.37349/edht.2023.00001
Twitter has been an invaluable social media platform for scientists to share research and host discourse among academics and the public. The change of ownership at Twitter has changed how scientists interact with the platform and has led some to worry about its future. This article discusses the current changes at Twitter and what implications these may have for future health research and communication.
Twitter has been an invaluable social media platform for scientists to share research and host discourse among academics and the public. The change of ownership at Twitter has changed how scientists interact with the platform and has led some to worry about its future. This article discusses the current changes at Twitter and what implications these may have for future health research and communication.
DOI: https://doi.org/10.37349/edht.2023.00002
This article belongs to the special issue Social Media Applications in Biomedical Research
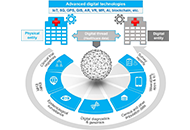
Digital technologies have garnered more attention in this epoch of public health emergencies like coronavirus disease 2019 (COVID-19) and monkeypox (mpox). Digital twin (DT) is the virtual cybernetic equivalent of a physical object (e.g., a device, a human, a community) used to better understand the complexity of the latter and predict, prevent, monitor, and optimize real-world outcomes. The possible use cases of DT systems in public health ranging from mass vaccination planning to understanding disease transmission patterns have been discussed. Despite potential applications in healthcare, several economic, social, and ethical challenges might hinder the universal implementation of DT. Nevertheless, devising appropriate policies, reinforcing good governance, and launching multinational collaborative efforts ascertain early espousal of DT technology.
Digital technologies have garnered more attention in this epoch of public health emergencies like coronavirus disease 2019 (COVID-19) and monkeypox (mpox). Digital twin (DT) is the virtual cybernetic equivalent of a physical object (e.g., a device, a human, a community) used to better understand the complexity of the latter and predict, prevent, monitor, and optimize real-world outcomes. The possible use cases of DT systems in public health ranging from mass vaccination planning to understanding disease transmission patterns have been discussed. Despite potential applications in healthcare, several economic, social, and ethical challenges might hinder the universal implementation of DT. Nevertheless, devising appropriate policies, reinforcing good governance, and launching multinational collaborative efforts ascertain early espousal of DT technology.
DOI: https://doi.org/10.37349/edht.2023.00003
This article belongs to the special issue Social Media Applications in Biomedical Research
Aim:
This study aimed to identify and analyze the top 100 most cited digital health and mobile health (m-health) publications. It could aid researchers in the identification of promising new research avenues, additionally supporting the establishment of international scientific collaboration between interdisciplinary research groups with demonstrated achievements in the area of interest.
Methods:
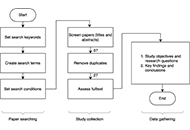
On 30th August, 2023, the Web of Science Core Collection (WOSCC) electronic database was queried to identify the top 100 most cited digital health papers with a comprehensive search string. From the initial search, 106 papers were identified. After screening for relevance, six papers were excluded, resulting in the final list of the top 100 papers. The basic bibliographic data was directly extracted from WOSCC using its “Analyze” and “Create Citation Report” functions. The complete records of the top 100 papers were downloaded and imported into a bibliometric software called VOSviewer (version 1.6.19) to generate an author keyword map and author collaboration map.
Results:
The top 100 papers on digital health received a total of 49,653 citations. Over half of them (n = 55) were published during 2013–2017. Among these 100 papers, 59 were original articles, 36 were reviews, 4 were editorial materials, and 1 was a proceeding paper. All papers were written in English. The University of London and the University of California system were the most represented affiliations. The USA and the UK were the most represented countries. The Journal of Medical Internet Research was the most represented journal. Several diseases and health conditions were identified as a focus of these works, including anxiety, depression, diabetes mellitus, cardiovascular diseases, and coronavirus disease 2019 (COVID-19).
Conclusions:
The findings underscore key areas of focus in the field and prominent contributors, providing a roadmap for future research in digital and m-health.
Aim:
This study aimed to identify and analyze the top 100 most cited digital health and mobile health (m-health) publications. It could aid researchers in the identification of promising new research avenues, additionally supporting the establishment of international scientific collaboration between interdisciplinary research groups with demonstrated achievements in the area of interest.
Methods:
On 30th August, 2023, the Web of Science Core Collection (WOSCC) electronic database was queried to identify the top 100 most cited digital health papers with a comprehensive search string. From the initial search, 106 papers were identified. After screening for relevance, six papers were excluded, resulting in the final list of the top 100 papers. The basic bibliographic data was directly extracted from WOSCC using its “Analyze” and “Create Citation Report” functions. The complete records of the top 100 papers were downloaded and imported into a bibliometric software called VOSviewer (version 1.6.19) to generate an author keyword map and author collaboration map.
Results:
The top 100 papers on digital health received a total of 49,653 citations. Over half of them (n = 55) were published during 2013–2017. Among these 100 papers, 59 were original articles, 36 were reviews, 4 were editorial materials, and 1 was a proceeding paper. All papers were written in English. The University of London and the University of California system were the most represented affiliations. The USA and the UK were the most represented countries. The Journal of Medical Internet Research was the most represented journal. Several diseases and health conditions were identified as a focus of these works, including anxiety, depression, diabetes mellitus, cardiovascular diseases, and coronavirus disease 2019 (COVID-19).
Conclusions:
The findings underscore key areas of focus in the field and prominent contributors, providing a roadmap for future research in digital and m-health.
DOI: https://doi.org/10.37349/edht.2024.00013
Background:
This study addresses the complexities of utilizing blockchain technology in healthcare, aiming to provide a decision-making tool for healthcare professionals and policymakers evaluating blockchain’s suitability for healthcare data sharing applications.
Methods:
A tertiary review was conducted on existing systematic literature reviews concerning blockchain in the healthcare domain. Reviews that focused on data sharing were selected, and common key factors assessing blockchain’s suitability in healthcare were extracted.
Results:
Our review synthesized findings from 27 systematic literature reviews, which led to the development of a refined decision-making flowchart. This tool outlines criteria such as scalability, integrity/immutability, interoperability, transparency, patient involvement, cost, and public verifiability, essential for assessing the suitability of blockchain in healthcare data sharing. This flowchart was validated through multiple case studies from various healthcare domains, testing its utility in real-world scenarios.
Discussion:
Blockchain technology could significantly benefit healthcare data sharing, provided its application is carefully evaluated against tailored criteria for healthcare needs. The decision-making flowchart developed from this review offers a systematic approach to assist stakeholders in navigating the complexities of implementing blockchain technology in healthcare settings.
Background:
This study addresses the complexities of utilizing blockchain technology in healthcare, aiming to provide a decision-making tool for healthcare professionals and policymakers evaluating blockchain’s suitability for healthcare data sharing applications.
Methods:
A tertiary review was conducted on existing systematic literature reviews concerning blockchain in the healthcare domain. Reviews that focused on data sharing were selected, and common key factors assessing blockchain’s suitability in healthcare were extracted.
Results:
Our review synthesized findings from 27 systematic literature reviews, which led to the development of a refined decision-making flowchart. This tool outlines criteria such as scalability, integrity/immutability, interoperability, transparency, patient involvement, cost, and public verifiability, essential for assessing the suitability of blockchain in healthcare data sharing. This flowchart was validated through multiple case studies from various healthcare domains, testing its utility in real-world scenarios.
Discussion:
Blockchain technology could significantly benefit healthcare data sharing, provided its application is carefully evaluated against tailored criteria for healthcare needs. The decision-making flowchart developed from this review offers a systematic approach to assist stakeholders in navigating the complexities of implementing blockchain technology in healthcare settings.
DOI: https://doi.org/10.37349/edht.2024.00014
This article belongs to the special issue Data-informed Decision Making in Healthcare
The aim of this contribution is to analyze and discuss the perturbations of body-onboard medical devices caused by electromagnetic field radiations. This involves their control via electromagnetic compatibility analysis and their protection against such perturbations. The wearable, detachable, and embedded devices are first presented and their monitoring, control, forecasting, and stimulating functions are detailed. The interaction of these devices with field exposures comprising their wireless routines is then analyzed. The perturbations control of onboard devices is investigated through the mathematical solution of governing electromagnetic field equations and their appropriate protection strategies are deliberated. The involved investigations and analyses in the contribution are supported by a literature review.
The aim of this contribution is to analyze and discuss the perturbations of body-onboard medical devices caused by electromagnetic field radiations. This involves their control via electromagnetic compatibility analysis and their protection against such perturbations. The wearable, detachable, and embedded devices are first presented and their monitoring, control, forecasting, and stimulating functions are detailed. The interaction of these devices with field exposures comprising their wireless routines is then analyzed. The perturbations control of onboard devices is investigated through the mathematical solution of governing electromagnetic field equations and their appropriate protection strategies are deliberated. The involved investigations and analyses in the contribution are supported by a literature review.
DOI: https://doi.org/10.37349/edht.2024.00015
Aim:
The social media platform X, formerly known as Twitter, has emerged as a significant hub for healthcare-related conversations and sharing information. This study aims to investigate the impact and reach of the #physiotherapy hashtag on the X platform.
Methods:
We collected and analyzed tweets containing the hashtag #physiotherapy posted between September 1, 2022, and September 1, 2023. Data was retrieved from X using the Fedica analytics platform on October 26, 2023. The data were analyzed and expressed in number and percentage and categorical data were tested by chi-square test.
Results:
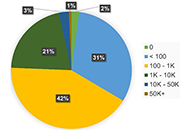
Over the course of one year, a total of 57,788 tweets were shared using #physiotherapy by 21,244 users, generating a remarkable 108,743,911 impressions. On average, there were 6 tweets posted per day (with a range from 3 to 9). Among the users, the majority (42%) had between 100 and 1000 followers, while 31.6% had fewer than 100 followers. The top three countries contributing to #physiotherapy tweets were the UK (29.9%), India (23.75%), and the USA (11.85%). An analysis of sentiment revealed that 84% of the tweets had a neutral tone, while 9% were positive and 7% were negative (P < 0.0001).
Conclusions:
The examination of tweets related to #physiotherapy unveiled a vibrant global dialogue, with active engagement from diverse backgrounds. Notably, contributions from the UK, India, and the USA were prominent.
Aim:
The social media platform X, formerly known as Twitter, has emerged as a significant hub for healthcare-related conversations and sharing information. This study aims to investigate the impact and reach of the #physiotherapy hashtag on the X platform.
Methods:
We collected and analyzed tweets containing the hashtag #physiotherapy posted between September 1, 2022, and September 1, 2023. Data was retrieved from X using the Fedica analytics platform on October 26, 2023. The data were analyzed and expressed in number and percentage and categorical data were tested by chi-square test.
Results:
Over the course of one year, a total of 57,788 tweets were shared using #physiotherapy by 21,244 users, generating a remarkable 108,743,911 impressions. On average, there were 6 tweets posted per day (with a range from 3 to 9). Among the users, the majority (42%) had between 100 and 1000 followers, while 31.6% had fewer than 100 followers. The top three countries contributing to #physiotherapy tweets were the UK (29.9%), India (23.75%), and the USA (11.85%). An analysis of sentiment revealed that 84% of the tweets had a neutral tone, while 9% were positive and 7% were negative (P < 0.0001).
Conclusions:
The examination of tweets related to #physiotherapy unveiled a vibrant global dialogue, with active engagement from diverse backgrounds. Notably, contributions from the UK, India, and the USA were prominent.
DOI: https://doi.org/10.37349/edht.2024.00016
This article belongs to the special issue Social Media Applications in Biomedical Research
Aim:
Longitudinal cohort study designs are considered the gold standard for investigating associations between environmental exposures and human health yet they are characterized by limitations including participant attrition, and the resource implications associated with cohort recruitment and follow-up. Attrition compromises the integrity of research by threatening both the internal and external validity of empirical results, weakening the accuracy of statistical inferences and the generalizability of findings. This pilot study aimed to trace participants from a historical cohort study, the Hamilton Child Cohort Study (HCC) (n = 3,202), (1976–1986, 2003–2008) which was originally designed to examine the relative contribution of indoor and outdoor exposure to air pollution on respiratory health.
Methods:
Original participants were traced through social networking sites (SNS) by leveraging personal identifying data (name, age, sex, educational affiliation, and geographical locations) from the HCC entered into SNS search engines.
Results:
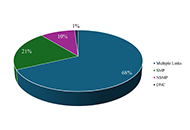
Of the original cohort (n = 3,166), 21% (n = 665) were identified as having social media presence (SMP) on a single social media platform, with 15% (n = 479) found on Facebook, 6% (n = 185) on LinkedIn, < 1% (n = 9) on Instagram, and n = 1 participant on Twitter. However, 68% (n = 2,168) of the cohort were associated with multiple SNS with the same features (matching names, ages, and locations), making conclusive identification challenging. The remaining 11% (n = 334) of the cohort had no SMP (NSMP). Statistical differences in sample characteristics of each cohort were analyzed using the Pearson chi-square test. Significant differences between the SMP and NSMP cohorts were found in relation to sex (p < 0.001), and childhood neighborhood of residence (p < 0.05).
Conclusions:
This study underscores social media’s potential for tracing participants in longitudinal studies while advising a multi-faceted approach to overcome inherent limitations and biases. A full-scale study is necessary to determine whether utilizing SNS to trace participants for longitudinal research is an effective tool for re-engaging research participants lost to attrition.
Aim:
Longitudinal cohort study designs are considered the gold standard for investigating associations between environmental exposures and human health yet they are characterized by limitations including participant attrition, and the resource implications associated with cohort recruitment and follow-up. Attrition compromises the integrity of research by threatening both the internal and external validity of empirical results, weakening the accuracy of statistical inferences and the generalizability of findings. This pilot study aimed to trace participants from a historical cohort study, the Hamilton Child Cohort Study (HCC) (n = 3,202), (1976–1986, 2003–2008) which was originally designed to examine the relative contribution of indoor and outdoor exposure to air pollution on respiratory health.
Methods:
Original participants were traced through social networking sites (SNS) by leveraging personal identifying data (name, age, sex, educational affiliation, and geographical locations) from the HCC entered into SNS search engines.
Results:
Of the original cohort (n = 3,166), 21% (n = 665) were identified as having social media presence (SMP) on a single social media platform, with 15% (n = 479) found on Facebook, 6% (n = 185) on LinkedIn, < 1% (n = 9) on Instagram, and n = 1 participant on Twitter. However, 68% (n = 2,168) of the cohort were associated with multiple SNS with the same features (matching names, ages, and locations), making conclusive identification challenging. The remaining 11% (n = 334) of the cohort had no SMP (NSMP). Statistical differences in sample characteristics of each cohort were analyzed using the Pearson chi-square test. Significant differences between the SMP and NSMP cohorts were found in relation to sex (p < 0.001), and childhood neighborhood of residence (p < 0.05).
Conclusions:
This study underscores social media’s potential for tracing participants in longitudinal studies while advising a multi-faceted approach to overcome inherent limitations and biases. A full-scale study is necessary to determine whether utilizing SNS to trace participants for longitudinal research is an effective tool for re-engaging research participants lost to attrition.
DOI: https://doi.org/10.37349/edht.2024.00017
This article belongs to the special issue Social Media Applications in Biomedical Research
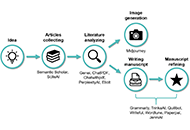
Artificial intelligence (AI) technology is advancing significantly, with many applications already in medicine, healthcare, and biomedical research. Among these fields, the area that AI is remarkably reshaping is biomedical scientific writing. Thousands of AI-based tools can be applied at every step of the writing process, improving time effectiveness, and streamlining authors’ workflow. Out of this variety, choosing the best software for a particular task may pose a challenge. While ChatGPT receives the necessary attention, other AI software should be addressed. In this review, we draw attention to a broad spectrum of AI tools to provide users with a perspective on which steps of their work can be improved. Several medical journals developed policies toward the usage of AI in writing. Even though they refer to the same technology, they differ, leaving a substantially gray area prone to abuse. To address this issue, we comprehensively discuss common ambiguities regarding AI in biomedical scientific writing, such as plagiarism, copyrights, and the obligation of reporting its implementation. In addition, this article aims to raise awareness about misconduct due to insufficient detection, lack of reporting, and unethical practices revolving around AI that might threaten unaware authors and medical society. We provide advice for authors who wish to implement AI in their daily work, emphasizing the need for transparency and the obligation together with the responsibility to maintain biomedical research credibility in the age of artificially enhanced science.
Artificial intelligence (AI) technology is advancing significantly, with many applications already in medicine, healthcare, and biomedical research. Among these fields, the area that AI is remarkably reshaping is biomedical scientific writing. Thousands of AI-based tools can be applied at every step of the writing process, improving time effectiveness, and streamlining authors’ workflow. Out of this variety, choosing the best software for a particular task may pose a challenge. While ChatGPT receives the necessary attention, other AI software should be addressed. In this review, we draw attention to a broad spectrum of AI tools to provide users with a perspective on which steps of their work can be improved. Several medical journals developed policies toward the usage of AI in writing. Even though they refer to the same technology, they differ, leaving a substantially gray area prone to abuse. To address this issue, we comprehensively discuss common ambiguities regarding AI in biomedical scientific writing, such as plagiarism, copyrights, and the obligation of reporting its implementation. In addition, this article aims to raise awareness about misconduct due to insufficient detection, lack of reporting, and unethical practices revolving around AI that might threaten unaware authors and medical society. We provide advice for authors who wish to implement AI in their daily work, emphasizing the need for transparency and the obligation together with the responsibility to maintain biomedical research credibility in the age of artificially enhanced science.
DOI: https://doi.org/10.37349/edht.2024.00024
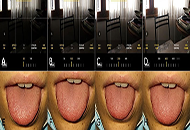
Photographic images are an essential tool in oral medicine practice, even though their value is conditioned by their quality. Digital photography using smartphones (SPhs) has had many advances, nowadays allowing the acquisition of high-quality pictures. Compared to professional cameras, it has advantages and disadvantages. The latter comprise photographs out of focus, poorly framed, and lighting problems due to shadows, artifacts, and color alterations, among other problems mainly mediated by the operator. Such defects can limit the proper interpretation of the image representing the patient’s condition. This perspective aims to describe the basic concepts of photography and the functional features of SPhs. This will allow programming those devices properly for oral telemedicine (OTM), understanding their limitations, and correcting errors for the photographs to be used effectively. We also include empirical solutions and illustrations showing that photography with SPhs could be easily executable by any health professional and even by the patients themselves.
Photographic images are an essential tool in oral medicine practice, even though their value is conditioned by their quality. Digital photography using smartphones (SPhs) has had many advances, nowadays allowing the acquisition of high-quality pictures. Compared to professional cameras, it has advantages and disadvantages. The latter comprise photographs out of focus, poorly framed, and lighting problems due to shadows, artifacts, and color alterations, among other problems mainly mediated by the operator. Such defects can limit the proper interpretation of the image representing the patient’s condition. This perspective aims to describe the basic concepts of photography and the functional features of SPhs. This will allow programming those devices properly for oral telemedicine (OTM), understanding their limitations, and correcting errors for the photographs to be used effectively. We also include empirical solutions and illustrations showing that photography with SPhs could be easily executable by any health professional and even by the patients themselves.
DOI: https://doi.org/10.37349/edht.2024.00025
This article belongs to the special issue Digital Health Technologies for the Early Detection of Oral Cancer
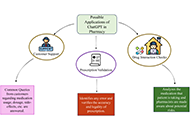
ChatGPT is one of the promising AI-based language models which has the potential to contribute to pharmacy settings in many aspects. This paper focuses on the possible aspects of pharmacy management where ChatGPT can contribute, the prevalence of its use in Saudi Arabia as a practical insight, case studies showing the potential of ChatGPT in answering health-related enquiries, its benefits, challenges, and future prospects of it. Helping clients, verifying medication, examining for potential reactions to drugs, identifying potential interaction between drugs, providing recommendation for suitable alternative medication therapies, assisting healthcare workers and supporting the search for novel medication are the biggest roles that are cited. The study highlights several benefits of using ChatGPT, including greater medical supervision, fewer drug errors, greater power over existing equipment, and support to study about the medicine sector. However, concerns about security, reliability, privacy, over-reliance on AI, and lack of natural judgement must be addressed by careful implementation under human review. The study also provided insight of practical application of ChatGPT in pharmacy education and possible ways of implementing ChatGPT in getting improved care and optimized operation. The future prospect of ChatGPT is promising but requires increased precision, integration of it into education programs, progressing of patient treatment and interaction, and facilitating novel research abilities. In general, the review suggests that ChatGPT has the potential to improve and modernize pharmacy processes but cautious implementation of this developing AI technology, combined with human knowledge is important to improve healthcare in the pharmaceutical field.
ChatGPT is one of the promising AI-based language models which has the potential to contribute to pharmacy settings in many aspects. This paper focuses on the possible aspects of pharmacy management where ChatGPT can contribute, the prevalence of its use in Saudi Arabia as a practical insight, case studies showing the potential of ChatGPT in answering health-related enquiries, its benefits, challenges, and future prospects of it. Helping clients, verifying medication, examining for potential reactions to drugs, identifying potential interaction between drugs, providing recommendation for suitable alternative medication therapies, assisting healthcare workers and supporting the search for novel medication are the biggest roles that are cited. The study highlights several benefits of using ChatGPT, including greater medical supervision, fewer drug errors, greater power over existing equipment, and support to study about the medicine sector. However, concerns about security, reliability, privacy, over-reliance on AI, and lack of natural judgement must be addressed by careful implementation under human review. The study also provided insight of practical application of ChatGPT in pharmacy education and possible ways of implementing ChatGPT in getting improved care and optimized operation. The future prospect of ChatGPT is promising but requires increased precision, integration of it into education programs, progressing of patient treatment and interaction, and facilitating novel research abilities. In general, the review suggests that ChatGPT has the potential to improve and modernize pharmacy processes but cautious implementation of this developing AI technology, combined with human knowledge is important to improve healthcare in the pharmaceutical field.
DOI: https://doi.org/10.37349/edht.2024.00026
In the United Kingdom (UK), the current prevalence rates of oropharyngeal cancer linked to human papillomavirus (HPV) are 6.29% and 2.04% in men and women, respectively. Over the years, the burden of this disease has increased in the UK, and this is mainly due to the rising prevalence of HPV infection in the UK. Research evidence has shown that over 70% of oropharyngeal cancers in the UK are linked to HPV. Oral sex is the major route of transmission of HPV, and over 63% of UK young adults are found to have a positive history of oral sex practice. However, only a minority of the UK population are aware of HPV-associated oropharyngeal cancer; this therefore calls for more public health efforts to increase awareness and knowledge on HPV-associated oropharyngeal cancer in the UK. While the use of technology-based, clinic-based, and community-based interventions have been employed to improve public awareness and knowledge on the role of HPV-associated oropharyngeal cancer, mobile health (mhealth) interventions have not been seriously explored despite existing robust evidence on the effective roles of mhealth in improving awareness and knowledge in diverse diseases. This article therefore calls for the adoption and use of mhealth interventions in educating the UK’s population on HPV-associated oropharyngeal cancer. The use of mhealth interventions in this regard is highly viable as its implementation closely aligns with the country’s National Health Service (NHS) commitment towards the digital transformation of the UK’s healthcare system.
In the United Kingdom (UK), the current prevalence rates of oropharyngeal cancer linked to human papillomavirus (HPV) are 6.29% and 2.04% in men and women, respectively. Over the years, the burden of this disease has increased in the UK, and this is mainly due to the rising prevalence of HPV infection in the UK. Research evidence has shown that over 70% of oropharyngeal cancers in the UK are linked to HPV. Oral sex is the major route of transmission of HPV, and over 63% of UK young adults are found to have a positive history of oral sex practice. However, only a minority of the UK population are aware of HPV-associated oropharyngeal cancer; this therefore calls for more public health efforts to increase awareness and knowledge on HPV-associated oropharyngeal cancer in the UK. While the use of technology-based, clinic-based, and community-based interventions have been employed to improve public awareness and knowledge on the role of HPV-associated oropharyngeal cancer, mobile health (mhealth) interventions have not been seriously explored despite existing robust evidence on the effective roles of mhealth in improving awareness and knowledge in diverse diseases. This article therefore calls for the adoption and use of mhealth interventions in educating the UK’s population on HPV-associated oropharyngeal cancer. The use of mhealth interventions in this regard is highly viable as its implementation closely aligns with the country’s National Health Service (NHS) commitment towards the digital transformation of the UK’s healthcare system.
DOI: https://doi.org/10.37349/edht.2024.00027
This article belongs to the special issue Digital Health Technologies for the Early Detection of Oral Cancer
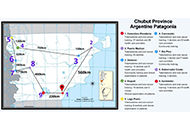
Geographic areas like Argentine Patagonia face significant barriers in the fight against oral cancer due to great distances, extreme weather conditions, and a shortage of specialists. These factors contribute to delayed diagnosis and treatment, adversely affecting patient outcomes. The aim of this study was to describe a pilot project to establish the telemedicine network of Chubut (Argentine Patagonia) for the early diagnosis of oral cancer. This perspective study also aimed to describe the advantages and disadvantages of using this tool in remote areas with limited access to healthcare services. Healthcare professionals, including nurses, dentists, doctors, and healthcare workers, were trained in the early diagnosis of oral cancer and high-risk oral lesions by five specialists in Oral Medicine, who traveled throughout Argentine Patagonia. Additionally, training was provided on the use of smartphones to obtain clinical images and data for remote consultations via telemedicine with a specialized center. Over 2,000 km were traveled, and more than 100 healthcare professionals were trained in six towns and localities in Patagonia, Argentina, encountering various limitations for the use of telemedicine in remote areas, such as connectivity issues. The first telemedicine network of Patagonia for the diagnosis of oral cancer was created and is now operational, receiving teleconsultations and referrals from the professionals trained during the journey. This study highlighted that telemedicine is an important tool to overcome geographical barriers and improve access to medical care, especially in remote areas. It promotes agility and speed in referrals and optimizes the available resources of the health system. Future studies should analyze the impact of telemedicine in decreasing the delay of oral cancer diagnosis in Southern Argentina.
Geographic areas like Argentine Patagonia face significant barriers in the fight against oral cancer due to great distances, extreme weather conditions, and a shortage of specialists. These factors contribute to delayed diagnosis and treatment, adversely affecting patient outcomes. The aim of this study was to describe a pilot project to establish the telemedicine network of Chubut (Argentine Patagonia) for the early diagnosis of oral cancer. This perspective study also aimed to describe the advantages and disadvantages of using this tool in remote areas with limited access to healthcare services. Healthcare professionals, including nurses, dentists, doctors, and healthcare workers, were trained in the early diagnosis of oral cancer and high-risk oral lesions by five specialists in Oral Medicine, who traveled throughout Argentine Patagonia. Additionally, training was provided on the use of smartphones to obtain clinical images and data for remote consultations via telemedicine with a specialized center. Over 2,000 km were traveled, and more than 100 healthcare professionals were trained in six towns and localities in Patagonia, Argentina, encountering various limitations for the use of telemedicine in remote areas, such as connectivity issues. The first telemedicine network of Patagonia for the diagnosis of oral cancer was created and is now operational, receiving teleconsultations and referrals from the professionals trained during the journey. This study highlighted that telemedicine is an important tool to overcome geographical barriers and improve access to medical care, especially in remote areas. It promotes agility and speed in referrals and optimizes the available resources of the health system. Future studies should analyze the impact of telemedicine in decreasing the delay of oral cancer diagnosis in Southern Argentina.
DOI: https://doi.org/10.37349/edht.2024.00028
This article belongs to the special issue Digital Health Technologies for the Early Detection of Oral Cancer
Teledentistry has emerged as a promising tool in bridging the gap in healthcare accessibility, particularly in regions like Latin America region, where resources for oral healthcare are often limited. Drawing upon a comprehensive review of literature, this overview assessed the applications and clinical outcomes of teledentistry in diagnosing oral potentially malignant disorders (OPMDs) and oral cancer, highlighting the challenges and opportunities specific to the Latin American context. Moreover, it examined the integration of artificial intelligence algorithms and teledentistry for enhancing diagnostic accuracy, thereby optimizing resource allocation and improving patient outcomes. By elucidating the current landscape and future prospects, this overview provided insights for policymakers, healthcare providers, and researchers, fostering advancements in oral healthcare delivery with the aim of reducing the burden of OPMDs and oral cancer in the Latin American region.
Teledentistry has emerged as a promising tool in bridging the gap in healthcare accessibility, particularly in regions like Latin America region, where resources for oral healthcare are often limited. Drawing upon a comprehensive review of literature, this overview assessed the applications and clinical outcomes of teledentistry in diagnosing oral potentially malignant disorders (OPMDs) and oral cancer, highlighting the challenges and opportunities specific to the Latin American context. Moreover, it examined the integration of artificial intelligence algorithms and teledentistry for enhancing diagnostic accuracy, thereby optimizing resource allocation and improving patient outcomes. By elucidating the current landscape and future prospects, this overview provided insights for policymakers, healthcare providers, and researchers, fostering advancements in oral healthcare delivery with the aim of reducing the burden of OPMDs and oral cancer in the Latin American region.
DOI: https://doi.org/10.37349/edht.2024.00029
This article belongs to the special issue Digital Health Technologies for the Early Detection of Oral Cancer
Aim:
In lung cancer research, AI has been trained to read chest radiographs, which has led to improved health outcomes. However, the use of AI in healthcare settings is not without its own set of drawbacks, with bias being primary among them. This study seeks to investigate AI bias in diagnosing and treating lung cancer patients. The research objectives of this study are threefold: 1) To determine which features of patient datasets are most susceptible to AI bias; 2) to then measure the extent of such bias; and 3) from the findings generated, offer recommendations for overcoming the pitfalls of AI in lung cancer therapy for the delivery of more accurate and equitable healthcare.
Methods:
We created a synthetic database consisting of 50 lung cancer patients using a large language model (LLM). We then used a logistic regression model to detect bias in AI-informed treatment plans.
Results:
The empirical results from our synthetic patient data illustrate AI bias along the lines of (1) patient demographics (specifically, age) and (2) disease classification/histology. As it concerns patient age, the model exhibited an accuracy rate of 82.7% for patients < 60 years compared to 85.7% for patients ≥ 60 years. Regarding disease type, the model was less adept in identifying treatment categories for adenocarcinoma (accuracy rate: 83.7%) than it was in predicting treatment categories for squamous cell carcinoma (accuracy rate: 92.3%).
Conclusions:
We address the implications of such results in terms of how they may exacerbate existing health disparities for certain patient populations. We conclude by outlining several strategies for addressing AI bias, including generating a more robust training dataset, developing software tools to detect bias, making the model’s code open access and soliciting user feedback, inviting oversight from an ethics review board, and augmenting patient datasets by synthesizing the underrepresented data.
Aim:
In lung cancer research, AI has been trained to read chest radiographs, which has led to improved health outcomes. However, the use of AI in healthcare settings is not without its own set of drawbacks, with bias being primary among them. This study seeks to investigate AI bias in diagnosing and treating lung cancer patients. The research objectives of this study are threefold: 1) To determine which features of patient datasets are most susceptible to AI bias; 2) to then measure the extent of such bias; and 3) from the findings generated, offer recommendations for overcoming the pitfalls of AI in lung cancer therapy for the delivery of more accurate and equitable healthcare.
Methods:
We created a synthetic database consisting of 50 lung cancer patients using a large language model (LLM). We then used a logistic regression model to detect bias in AI-informed treatment plans.
Results:
The empirical results from our synthetic patient data illustrate AI bias along the lines of (1) patient demographics (specifically, age) and (2) disease classification/histology. As it concerns patient age, the model exhibited an accuracy rate of 82.7% for patients < 60 years compared to 85.7% for patients ≥ 60 years. Regarding disease type, the model was less adept in identifying treatment categories for adenocarcinoma (accuracy rate: 83.7%) than it was in predicting treatment categories for squamous cell carcinoma (accuracy rate: 92.3%).
Conclusions:
We address the implications of such results in terms of how they may exacerbate existing health disparities for certain patient populations. We conclude by outlining several strategies for addressing AI bias, including generating a more robust training dataset, developing software tools to detect bias, making the model’s code open access and soliciting user feedback, inviting oversight from an ethics review board, and augmenting patient datasets by synthesizing the underrepresented data.
DOI: https://doi.org/10.37349/edht.2024.00030
Background:
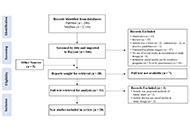
Social media has become ubiquitous; its uses reach beyond connecting individuals or organizations. Many biomedical researchers have found social media to be a useful tool in recruiting patients for clinical studies, crowdsourcing for cross-sectional studies, and even as a method of intervention. Social media usefulness in biomedical research has largely been in population health and non-surgical specialties, however, its usefulness in surgical specialties should not be overlooked. Specifically in plastic surgery, social media use to understand patient perceptions, identify populations, and provide care has become an important part of clinical practice.
Methods:
A scoping review was performed utilizing PubMed and Medline databases, and articles were screened for the use of social media as a method of recruitment to a clinical trial, as crowdsourcing (i.e., recruitment for a cross-sectional or survey-based study), or as a method of intervention.
Results:
A total of 28 studies were included, which focused on majority females between 18–34 years old. Despite the ability of the internet and social media to connect people worldwide, nearly all the studies focused on the researchers’ home countries. The studies largely focused on social media’s effect on self-esteem and acceptance of cosmetic surgery, but other notable trends were analyses of patient perceptions of a disease, or surgical outcomes as reported in social media posts.
Discussion:
Overall, social media can be a useful tool for plastic surgeons looking to recruit patients for a survey-based study or crowdsourcing of information.
Background:
Social media has become ubiquitous; its uses reach beyond connecting individuals or organizations. Many biomedical researchers have found social media to be a useful tool in recruiting patients for clinical studies, crowdsourcing for cross-sectional studies, and even as a method of intervention. Social media usefulness in biomedical research has largely been in population health and non-surgical specialties, however, its usefulness in surgical specialties should not be overlooked. Specifically in plastic surgery, social media use to understand patient perceptions, identify populations, and provide care has become an important part of clinical practice.
Methods:
A scoping review was performed utilizing PubMed and Medline databases, and articles were screened for the use of social media as a method of recruitment to a clinical trial, as crowdsourcing (i.e., recruitment for a cross-sectional or survey-based study), or as a method of intervention.
Results:
A total of 28 studies were included, which focused on majority females between 18–34 years old. Despite the ability of the internet and social media to connect people worldwide, nearly all the studies focused on the researchers’ home countries. The studies largely focused on social media’s effect on self-esteem and acceptance of cosmetic surgery, but other notable trends were analyses of patient perceptions of a disease, or surgical outcomes as reported in social media posts.
Discussion:
Overall, social media can be a useful tool for plastic surgeons looking to recruit patients for a survey-based study or crowdsourcing of information.
DOI: https://doi.org/10.37349/edht.2024.00031
This article belongs to the special issue Social Media Applications in Biomedical Research
Aim:
AI research, development, and implementation are expanding at an exponential pace across healthcare. This paradigm shift in healthcare research has led to increased demands for clinical outcomes, all at the expense of a significant gap in AI literacy within the healthcare field. This has further translated to a lack of tools in creating a framework for literature in the AI in medicine domain. We propose HUMANE (Harmonious Understanding of Machine Learning Analytics Network), a checklist for establishing an international consensus for authors and reviewers involved in research focused on artificial intelligence (AI) or machine learning (ML) in medicine.
Methods:
This study was conducted using the Delphi method by devising a survey using the Google Forms platform. The survey was developed as a checklist containing 8 sections and 56 questions with a 5-point Likert scale.
Results:
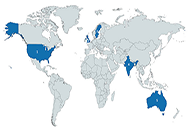
A total of 33 survey respondents were part of the initial Delphi process with the majority (45%) in the 36–45 years age group. The respondents were located across the USA (61%), UK (24%), and Australia (9%) as the top 3 countries, with a pre-dominant healthcare background (42%) as early-career professionals (3–10 years’ experience) (42%). Feedback showed an overall agreeable consensus (mean ranges 4.1–4.8, out of 5) as cumulative scores throughout all sections. The majority of the consensus was agreeable with the Discussion (Other) section of the checklist (median 4.8 (interquartile range (IQR) 4.8-4.8)), whereas the least agreed section was the Ground Truth (Expert(s) review) section (median 4.1 (IQR 3.9–4.2)) and the Methods (Outcomes) section (median 4.1 (IQR 4.1–4.1)) of the checklist. The final checklist after consensus and revision included a total of 8 sections and 50 questions.
Conclusions:
The HUMANE international consensus has reflected on further research on the potential of this checklist as an established consensus in improving the reliability and quality of research in this field.
Aim:
AI research, development, and implementation are expanding at an exponential pace across healthcare. This paradigm shift in healthcare research has led to increased demands for clinical outcomes, all at the expense of a significant gap in AI literacy within the healthcare field. This has further translated to a lack of tools in creating a framework for literature in the AI in medicine domain. We propose HUMANE (Harmonious Understanding of Machine Learning Analytics Network), a checklist for establishing an international consensus for authors and reviewers involved in research focused on artificial intelligence (AI) or machine learning (ML) in medicine.
Methods:
This study was conducted using the Delphi method by devising a survey using the Google Forms platform. The survey was developed as a checklist containing 8 sections and 56 questions with a 5-point Likert scale.
Results:
A total of 33 survey respondents were part of the initial Delphi process with the majority (45%) in the 36–45 years age group. The respondents were located across the USA (61%), UK (24%), and Australia (9%) as the top 3 countries, with a pre-dominant healthcare background (42%) as early-career professionals (3–10 years’ experience) (42%). Feedback showed an overall agreeable consensus (mean ranges 4.1–4.8, out of 5) as cumulative scores throughout all sections. The majority of the consensus was agreeable with the Discussion (Other) section of the checklist (median 4.8 (interquartile range (IQR) 4.8-4.8)), whereas the least agreed section was the Ground Truth (Expert(s) review) section (median 4.1 (IQR 3.9–4.2)) and the Methods (Outcomes) section (median 4.1 (IQR 4.1–4.1)) of the checklist. The final checklist after consensus and revision included a total of 8 sections and 50 questions.
Conclusions:
The HUMANE international consensus has reflected on further research on the potential of this checklist as an established consensus in improving the reliability and quality of research in this field.
DOI: https://doi.org/10.37349/edht.2024.00018
Information and communication technologies (ICTs) have transformed global connectivity, offering significant support to underserved populations and small businesses in developing nations. The integration of social media into the ICT landscape has further revolutionized communication and information sharing worldwide. However, despite its widespread adoption, the precise impact of social media on biomedical research remains uncertain. This manuscript seeks to examine the multifaceted roles of social media in healthcare, focusing on its applications in patient care, professional networking, education, organizational promotion, and public health programs. Additionally, it investigates social media’s significance in research, particularly its potential for data collection and analysis. A comprehensive literature review was undertaken to consolidate existing knowledge on social media’s utilization in healthcare and research. Various platforms, including social networking sites and academic networking sites, were assessed, along with their respective applications and consequences. Social media platforms have become essential tools in healthcare, facilitating professional networking, patient education, organizational promotion, and public health initiatives. In the realm of research, social media provides extensive opportunities for data collection, analysis, and collaboration, although challenges persist regarding privacy, data accuracy, and ethical considerations. The pervasive influence of social media in healthcare and research highlights its potential to enhance communication, engagement, and knowledge dissemination. However, careful adherence to ethical guidelines and privacy concerns is essential to maximize its benefits while minimizing risks. As social media continues to evolve, its role in shaping biomedical research and healthcare practices is anticipated to grow, necessitating ongoing exploration and adaptation by stakeholders.
Information and communication technologies (ICTs) have transformed global connectivity, offering significant support to underserved populations and small businesses in developing nations. The integration of social media into the ICT landscape has further revolutionized communication and information sharing worldwide. However, despite its widespread adoption, the precise impact of social media on biomedical research remains uncertain. This manuscript seeks to examine the multifaceted roles of social media in healthcare, focusing on its applications in patient care, professional networking, education, organizational promotion, and public health programs. Additionally, it investigates social media’s significance in research, particularly its potential for data collection and analysis. A comprehensive literature review was undertaken to consolidate existing knowledge on social media’s utilization in healthcare and research. Various platforms, including social networking sites and academic networking sites, were assessed, along with their respective applications and consequences. Social media platforms have become essential tools in healthcare, facilitating professional networking, patient education, organizational promotion, and public health initiatives. In the realm of research, social media provides extensive opportunities for data collection, analysis, and collaboration, although challenges persist regarding privacy, data accuracy, and ethical considerations. The pervasive influence of social media in healthcare and research highlights its potential to enhance communication, engagement, and knowledge dissemination. However, careful adherence to ethical guidelines and privacy concerns is essential to maximize its benefits while minimizing risks. As social media continues to evolve, its role in shaping biomedical research and healthcare practices is anticipated to grow, necessitating ongoing exploration and adaptation by stakeholders.
DOI: https://doi.org/10.37349/edht.2024.00019
This article belongs to the special issue Social Media Applications in Biomedical Research
